Доктор Дао Дык Минь: «Освоение вьетнамских данных — это первый шаг к развитию и освоению вьетнамских технологий»
Báo Thanh niên•27/05/2024
Проработав в крупной организации, занимающейся искусственным интеллектом в США, почему вы решили вернуться во Вьетнам и присоединиться к VinBigdata? Работая в США, я участвовал во многих крупных государственных проектах, но результаты, которых я достиг, зачастую были лишь несколькими этапами в обширном процессе обработки данных. Из-за строгих процедур конфиденциальности проектов я часто даже не знал, как используются разработанные мной решения. В 2017 году я вернулся во Вьетнам, когда Вьетнам находился на этапе развития, и существовало множество проблем, связанных с большими данными и искусственным интеллектом, которые требовали решения. Я принял приглашение профессора Ву Ха Вана для совместной работы над целью разработки вьетнамских технологических решений, которые будут служить жизни вьетнамцев. Я считаю своё возвращение во Вьетнам гораздо более значимым, поскольку смогу работать над проблемами, имеющими более весомое значение.
Доктор Дао Дык Минь в мастерской
NVCC
Какова роль и влияние больших данных в стратегии развития искусственного интеллекта, сэр? Данные играют очень важную и ценную роль в обучении искусственного интеллекта. Чтобы обучить высококачественную модель искусственного интеллекта, мы часто начинаем с обучения большой базы данных. Поэтому, чтобы иметь качественный искусственный интеллект, нам сначала нужны хорошие данные. Хорошие данные должны соответствовать стандартам с точки зрения количества и масштаба, качества, разнообразия и универсальности. Процесс сбора и обработки тысяч часов данных, начиная с этапа очистки необработанных данных и заканчивая созданием данных высочайшего качества для подачи в модель искусственного интеллекта, очень дорогой и сложный. Напротив, для анализа больших данных нам необходимо использовать искусственный интеллект, чтобы гарантировать возможность точной обработки данных в больших масштабах, тем самым создавая более решающие или предсказательные результаты. Например, при разработке виртуального помощника для вьетнамцев (ViVi) нам пришлось собрать и обработать десятки тысяч часов высококачественных аудиоданных, полученных от сотен тысяч голосов из разных регионов, людей разных возрастов и полов, с контентом, охватывающим сотни тематик... Или совсем недавно, запуск ViGPT — «первой вьетнамской версии ChatGPT для конечных пользователей», разработанной на основе Big Language Model, полностью принадлежащей VinBigdata. Эта модель была обучена на основе 600 ГБ уточнённых вьетнамских данных из множества различных тематик. Благодаря нашему пониманию вьетнамских данных и языка, мы нашли новый подход к сокращению времени запуска ViGPT до всего 9 месяцев после появления ChatGPT. Это резонанс между большими данными и искусственным интеллектом.
Что вы думаете о связи исследований с практической пользой для общества? — Я считаю, что технологические исследования по-настоящему успешны только тогда, когда они воплощаются в жизнь, решают социальные проблемы и улучшают жизнь людей. Чтобы создавать практичные коммерческие продукты и решать бизнес- и социальные проблемы, мы всегда должны обращать внимание на вопрос: какую ценность данные привносят в жизнь? К настоящему времени мы исследовали множество продуктов и решений в различных отраслях и областях, в частности, ViGPT, VinDr — решения на основе ИИ для медицинской визуализации, VinBase — платформу для искусственного интеллекта и Vizone — набор интеллектуальных решений для анализа изображений.
С ключевыми сотрудниками VinBigdata на мероприятии корпорации Vingroup
NVCC
Четвёртая промышленная революция активно развивается в глобальном масштабе. Какие преимущества, по вашему мнению, есть у Вьетнама? По сравнению с предыдущими революциями, я думаю, у Вьетнама сейчас есть много преимуществ для прорыва в этой четвёртой промышленной революции, что поможет улучшить положение страны на карте мира . Два ключа к достижению этой цели — данные и люди. В настоящее время во Вьетнаме проживает почти 100 миллионов человек, из которых значительная доля молодёжи пользуется телефонами и персональными компьютерами. Кроме того, у нас есть авторитетные специалисты в области искусственного интеллекта, молодые высококвалифицированные специалисты в области информационных технологий и очень хорошая математическая база. Так как же насчёт ограничений? Первое ограничение, которое можно увидеть, заключается в том, что, несмотря на большую численность населения, мы всё ещё испытываем трудности с управлением данными, в частности, со стандартизацией и синхронизацией данных на объектах, в бизнес-подразделениях и администрациях. Кроме того, мы сталкиваемся и с другими ограничениями, такими как ограниченные инвестиционные ресурсы, особенно инвестиции в высокопроизводительную вычислительную инфраструктуру.
Насколько, по вашему мнению, важно овладение вьетнамскими данными на пути создания и освоения технологий, служащих жизни вьетнамцев? В настоящее время существует множество ведущих мировых продуктов искусственного интеллекта, в основном, приложений ИИ, созданных на основе крупных языковых моделей, таких как ChatGPT от OpenAI или Bard от Google. Однако вьетнамский язык не является основной языковой группой для разработки этих продуктов. Поэтому качество контента на вьетнамском языке, возвращаемого пользователям, в той или иной степени страдает и имеет высокую вероятность ошибок, что ещё опаснее, ошибок в базовых знаниях. Будучи вьетнамцами, мы имеем преимущество доступа к собственным источникам данных. Только мы способны понимать особенности вьетнамских данных, потребности и особенности вьетнамцев. Таким образом, овладение вьетнамскими данными действительно является ключом к овладению основными технологиями, которые также будут служить вьетнамцам.
Внутреннее обучение для участников VinBigdata
NVCC
Как получить доступ к конкретным источникам данных, особенно учитывая, что большинство вьетнамцев сегодня пользуются социальными сетями из-за рубежа? Фактически, крупнейшим источником данных о людях (не только о вьетнамцах) сегодня являются интернет и социальные сети. Тем не менее, мы по-прежнему можем получать доступ к данным и собирать их из различных источников, основываясь на понимании характеристик вьетнамских данных, в зависимости от характеристик, задаваемых каждым проектом. Например, модели GPT OpenAI имеют сотни, а то и триллионы параметров, обучаются на огромных объёмах данных и стоят миллиарды долларов. В отличие от них, мы выбрали совершенно иное направление, основанное на наших исследованиях, возможностях и ресурсах: создание модели вьетнамского языка с архитектурой всего из нескольких миллиардов параметров, обученной на наборе вьетнамских данных объёмом 600 ГБ, который мы собрали и обработали самостоятельно, но с такой же способностью обрабатывать вьетнамский язык. Результаты показывают, что наша собственная архитектура способна к самооптимизации, сокращению времени обучения языковой модели, снижению затрат при сохранении её качества. С какими трудностями вы и ваша команда столкнулись в процессе исследования и разработки продуктов искусственного интеллекта? Первая проблема, безусловно, — это время. Волна технологий искусственного интеллекта надвигается очень быстро и переживает период бурного развития. Ведущие мировые технологические компании быстро выпустили высококомплексные продукты, которые постоянно обновляются и совершенствуются. Если мы будем медлить и не выпустим продукты вовремя, мы неизбежно отстанем. С другой стороны, если мы хотим создавать продукты, которые можно применять на практике и решать практические социальные проблемы, мы должны также искать и развивать выдающиеся, особые и уникальные характеристики продукта.
Презентация на Дне искусственного интеллекта во Вьетнаме (AI4VN 2023)
NVCC
Фактически, многие люди и организации во Вьетнаме и по всему миру понесли огромные потери из-за утечек данных. Как вы оцениваете проблему безопасности данных? Можно сказать, что любое приложение сегодня основано на данных. Работая с данными, мы, с одной стороны, должны обеспечить цель применения данных для создания лучших технологий для жизни, а с другой стороны, мы должны обеспечить безопасность данных для людей и организаций. Человеческий фактор является очень важным звеном в процессе обеспечения безопасности данных. К ним относятся разработчики, пользователи продукта и сами пользователи. Разработчики должны осознавать важность безопасности данных с самого начала сбора и обработки данных. Часто, когда проблем не возникает, мы не осознаем важности безопасности данных. Но если происходит утечка данных, ущерб может быть огромным. Утечки данных могут происходить из-за технических проблем или преднамеренных атак с целью кражи данных. В случае утечки данных информация отдельных лиц или организаций может быть использована злоумышленниками в незаконных целях, в то время как компании могут понести финансовые потери из-за необходимости устранения связанных с этим проблем и даже нанести ущерб своему бренду.
Доктор Дао Дык Минь и команда VinBigdata на мероприятии
NVCC
После стремления освоить технологии на благо вьетнамского народа, необходимо предпринять шаги для выхода на мировой рынок. Любая организация или предприятие, стремящееся вывести свою продукцию на международный рынок, должно соответствовать международным стандартам. VinBigdata обладает сильными сторонами в области решений и технологий, поэтому постановка цели покорить мир естественна. Конечно, для внедрения решений для множества различных продуктов и приложений необходимо сотрудничество международных подразделений с многолетним опытом и пониманием потребностей пользователей по всему миру. Спасибо!



 Проработав в крупной организации, занимающейся искусственным интеллектом в США, почему вы решили вернуться во Вьетнам и присоединиться к VinBigdata? Работая в США, я участвовал во многих крупных государственных проектах, но результаты, которых я достиг, зачастую были лишь несколькими этапами в обширном процессе обработки данных. Из-за строгих процедур конфиденциальности проектов я часто даже не знал, как используются разработанные мной решения. В 2017 году я вернулся во Вьетнам, когда Вьетнам находился на этапе развития, и существовало множество проблем, связанных с большими данными и искусственным интеллектом, которые требовали решения. Я принял приглашение профессора Ву Ха Вана для совместной работы над целью разработки вьетнамских технологических решений, которые будут служить жизни вьетнамцев. Я считаю своё возвращение во Вьетнам гораздо более значимым, поскольку смогу работать над проблемами, имеющими более весомое значение.
Проработав в крупной организации, занимающейся искусственным интеллектом в США, почему вы решили вернуться во Вьетнам и присоединиться к VinBigdata? Работая в США, я участвовал во многих крупных государственных проектах, но результаты, которых я достиг, зачастую были лишь несколькими этапами в обширном процессе обработки данных. Из-за строгих процедур конфиденциальности проектов я часто даже не знал, как используются разработанные мной решения. В 2017 году я вернулся во Вьетнам, когда Вьетнам находился на этапе развития, и существовало множество проблем, связанных с большими данными и искусственным интеллектом, которые требовали решения. Я принял приглашение профессора Ву Ха Вана для совместной работы над целью разработки вьетнамских технологических решений, которые будут служить жизни вьетнамцев. Я считаю своё возвращение во Вьетнам гораздо более значимым, поскольку смогу работать над проблемами, имеющими более весомое значение. 







![[Фото] Генеральный секретарь То Лам принимает участие в праздновании 80-летия традиционного Дня сектора культуры](https://vstatic.vietnam.vn/vietnam/resource/IMAGE/2025/8/23/7a88e6b58502490aa153adf8f0eec2b2)




![[Фото] Премьер-министр Фам Минь Чинь председательствует на заседании Постоянного комитета Правительственного партийного комитета](https://vstatic.vietnam.vn/vietnam/resource/IMAGE/2025/8/23/8e94aa3d26424d1ab1528c3e4bbacc45)



























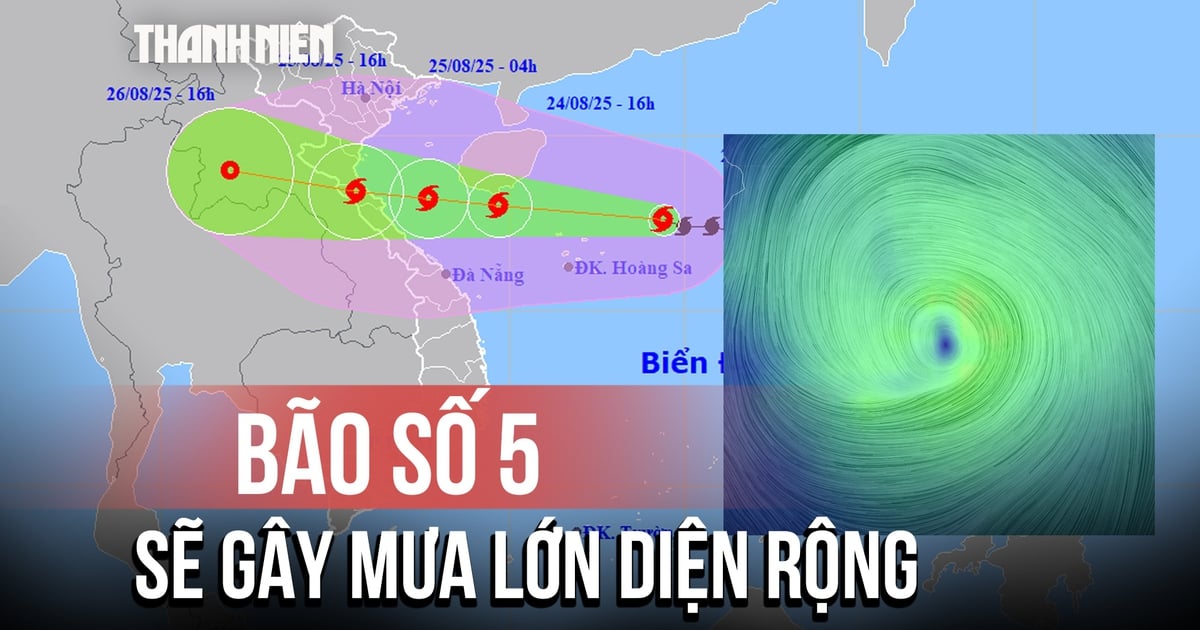

























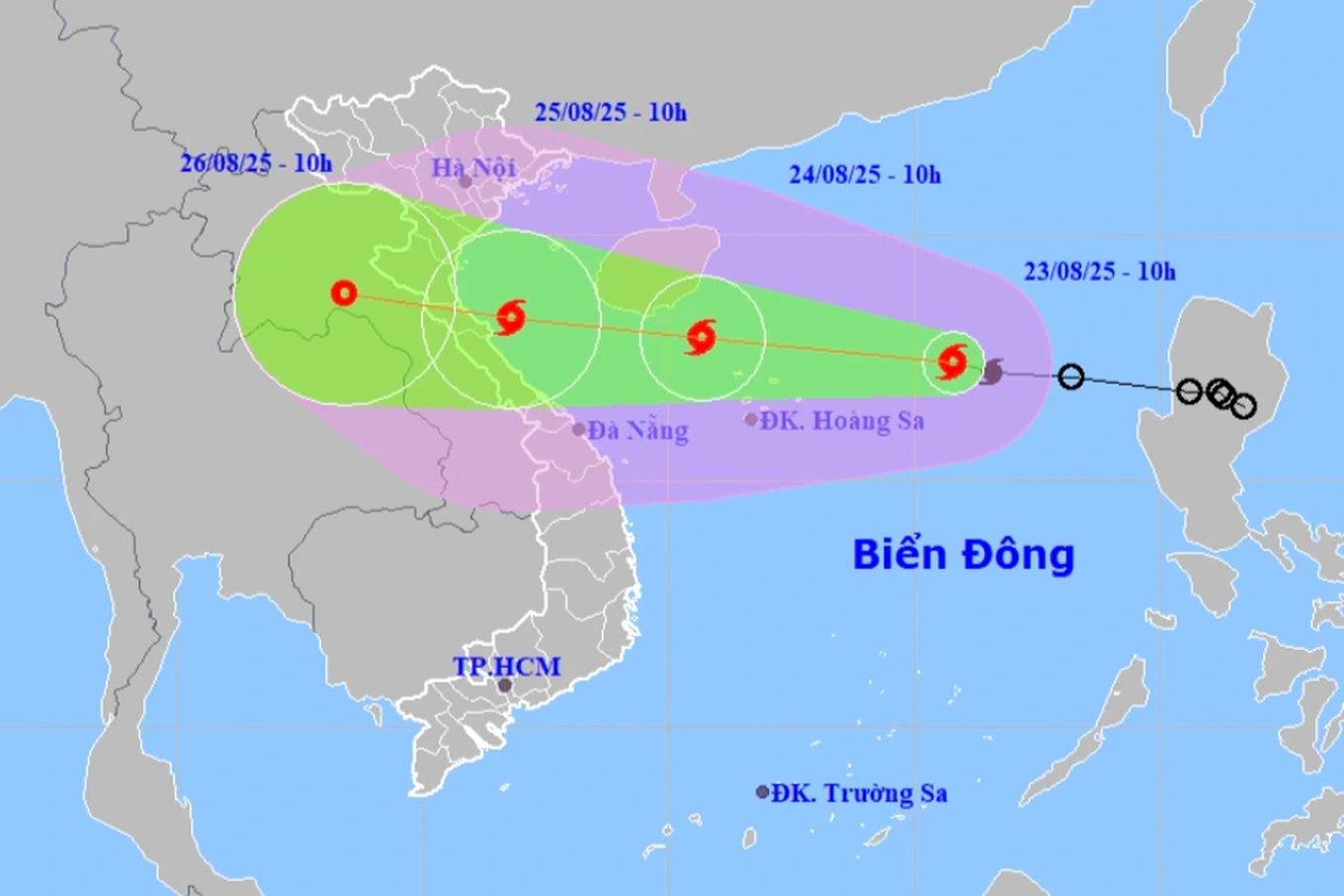



































Комментарий (0)